
The Tech Buffet #18: Advanced Retrieval Techniques for RAG
Query expansion, cross-encoder re-ranking and embedding adaptors

The Tech Buffet demystifies complex topics in programming and ML and delivers practical tips from the industry.
100% bulsh** free, 0% ChatGPT content.
Subscribe for the good stuff 👇

Today’s issue will cover 3 powerful techniques that efficiently improve document retrieval in RAG-based applications.
Query expansion
Cross-encoder re-ranking
Embedding adaptors
By implementing them, you will retrieve more relevant documents that better align with the user query, thus making the generated answer more impactful.
1— Query expansion
Query expansion refers to a set of techniques that rephrase the original query.
We’ll look at two methods:
👉 Query expansion with a generated answer
Given an input query, this method first instructs an LLM to provide a hypothetical answer, whatever its correctness.
Then, the query and the generated answer are combined in a prompt and sent to the retrieval system.

This technique surprisingly works well. Check the findings of this paper to learn more about it.
The rationale behind this method is that we want to retrieve documents that look more like an answer. The correctness of the hypothetical answer doesn’t matter much because what we’re really interested in is its structure and formulation.
At best, you could consider the hypothetical answer as a template that helps identify a relevant neighborhood in the embedding space.
Here’s an example of a prompt I used to augment the query for a RAG that answers questions about financial reports.
You are a helpful expert financial research assistant.
Provide an example answer to the given question, that might be found in a document like an annual report.👉 Query expansion with multiple related questions
This second method instructs an LLM to generate N questions related to the original query and then sends them all (+ the original query) to the retrieval system.
By doing this, more documents will be retrieved from the vectorstore. However, some of them will be duplicates which is why you need to perform post-processing.

The idea behind this method is that you extend the initial query that may be incomplete and incorporate related aspects that can be eventually relevant and complementary.
Here’s a prompt I used to generate related questions:
You are a helpful expert financial research assistant.
Your users are asking questions about an annual report.
Suggest up to five additional related questions to help them find the information they need, for the provided question.
Suggest only short questions without compound sentences. Suggest a variety of questions that cover different aspects of the topic.
Make sure they are complete questions, and that they are related to the original question.
Output one question per line. Do not number the questions."The downside of this method is that we end up with a lot more documents that may distract the LLM from generating a useful answer.
That’s where re-ranking comes into play.
To learn more about different query expansion techniques, check this paper for Google.
2—Cross encoder re-ranking
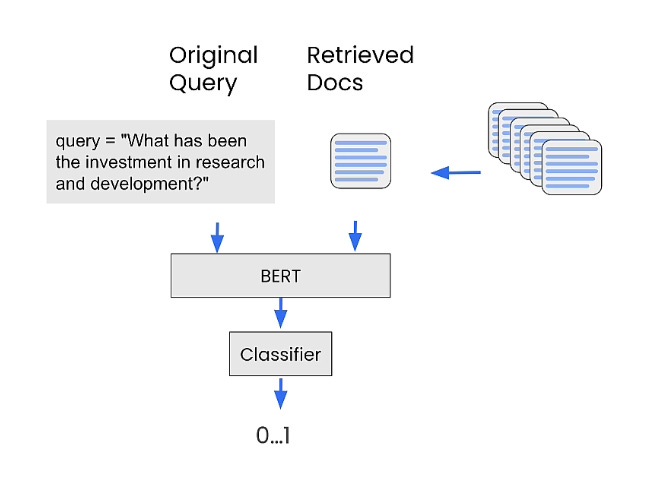
This method re-ranks the retrieved documents according to a score that quantifies their relevancy with the input query.

To compute this score, we will use a cross-encoder.
A cross-encoder is a deep neural network that processes two input sequences together as a single input. This allows the model to directly compare and contrast the inputs, understanding their relationship in a more integrated and nuanced way.

Cross-encoders can be used for Information Retrieval: given a query, encode the query with all retrieved documents. Then, sort them in a decreasing order. The high-scored documents are the most relevant ones.
See SBERT.net Retrieve & Re-rank for more details.
Here’s how to quickly get started with re-ranking using cross-encoders:
Install sentence-transformers:
pip install -U sentence-transformersImport the cross-encoder and load it:
from sentence_transformers import CrossEncoder cross_encoder = CrossEncoder('cross-encoder/ms-marco-MiniLM-L-6-v2')Score each pair of (query, document):
pairs = [[query, doc] for doc in retrieved_documents] scores = cross_encoder.predict(pairs) print("Scores:") for score in scores: print(score) Scores: 0.98693466 2.644579 -0.26802942 -10.73159 -7.7066045 -5.6469955 -4.297035 -10.933233 -7.0384283 -7.3246956Reorder the documents:
print("New Ordering:") for o in np.argsort(scores)[::-1]: print(o+1)
Cross-encoder re-ranking can be used with query expansion: after you generate multiple related questions and retrieve the corresponding documents (say you end up with M documents), you re-rank them and pick the top K (K < M).
That way, you reduce the context size while selecting the most important pieces.
In the next section, we’re going to dive into adaptors, a powerful yet simple-to-implement technique to scale embeddings to better align with the user’s task.
