
The Tech Buffet #19: How To Build and Deploy an LLM-Powered App To Chat with PapersWithCode
Keep up with the latest ML research

Hey there 👋 Happy to have you here. Today’s issue is a practical end-to-end tutorial that’ll teach you how to build and deploy a personal assistant to digest the recent ML research.
Subscribe to access the full material of this issue

Do you find it difficult to keep up with the latest ML research? Are you overwhelmed with the massive amount of papers about LLMs, vector databases, or RAGs?
In this issue, I will show how to build an AI assistant that mines this large amount of information easily. You’ll ask it your questions in natural language and it’ll answer according to relevant papers it finds on Papers With Code.
⚙️ On the backend side, this assistant will be powered with a Retrieval Augmented Generation (RAG) framework that relies on a scalable serverless vector database, an embedding model from VertexAI, and an LLM from OpenAI.
💻 On the front-end side, this assistant will be integrated into an interactive web application built with Streamlit and deployed on Google Cloud Run.
Every step of this process will be detailed below with an accompanying source code that you can reuse and adapt👇.
Before we start, here’s the global app workflow:

And here’s the agenda:
1. Collect data from Papers With Code
2. Create an index on Upstash
3. Embed the chunks and index them
4. Ask questions about the indexed papers
5. Build a Streamlit application
6. Deploy the Streamlit application on Google Cloud Run
PS: You can reuse every piece of code shared in this issue and adapt it to your personal or professional projects.
Ready? Let’s dive in 🔍.
1. Collect data from Papers With Code
Papers With Code (a.k.a PWC) is a free website for researchers and practitioners to find and follow the latest state-of-the-art ML papers, source code, and datasets.
It’s also possible to interact with PWC through an API to programmatically retrieve research papers. If you look at this Swagger UI, you can find all the available endpoints and try them out.
Let’s, for example, search papers on a specific keyword.
Here’s how to do it from the interface: you locate the papers/ endpoint, fill in the query ( q ) argument.

and hit the execute button.
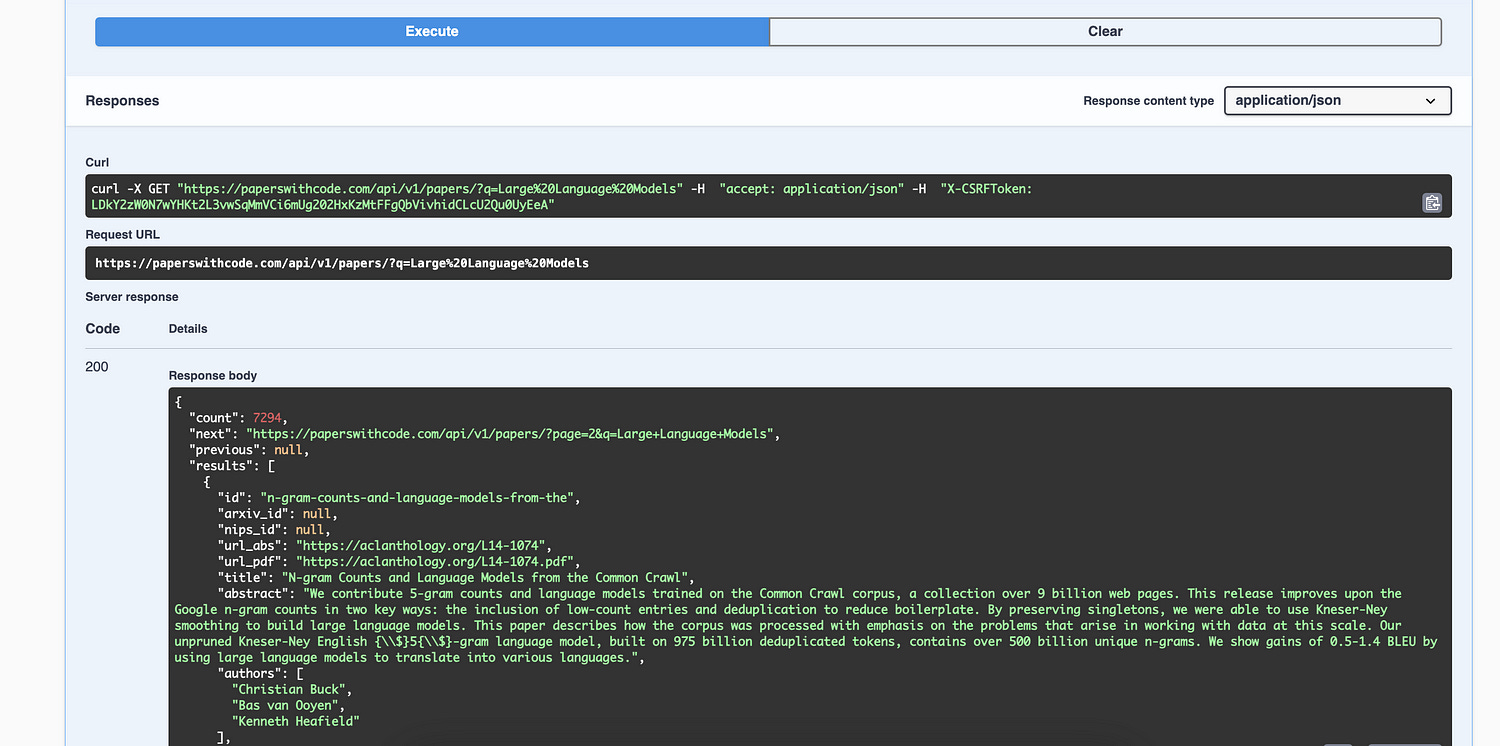
Equivalently, you can perform this same search by hitting this URL.
The output response shows the first page of results only. The following pages are available by accessing the next key.
By exploiting this structure, we can retrieve 7200 papers matching “Large Language Models”. This can be done with a function that requests the URL and loops over all the pages.

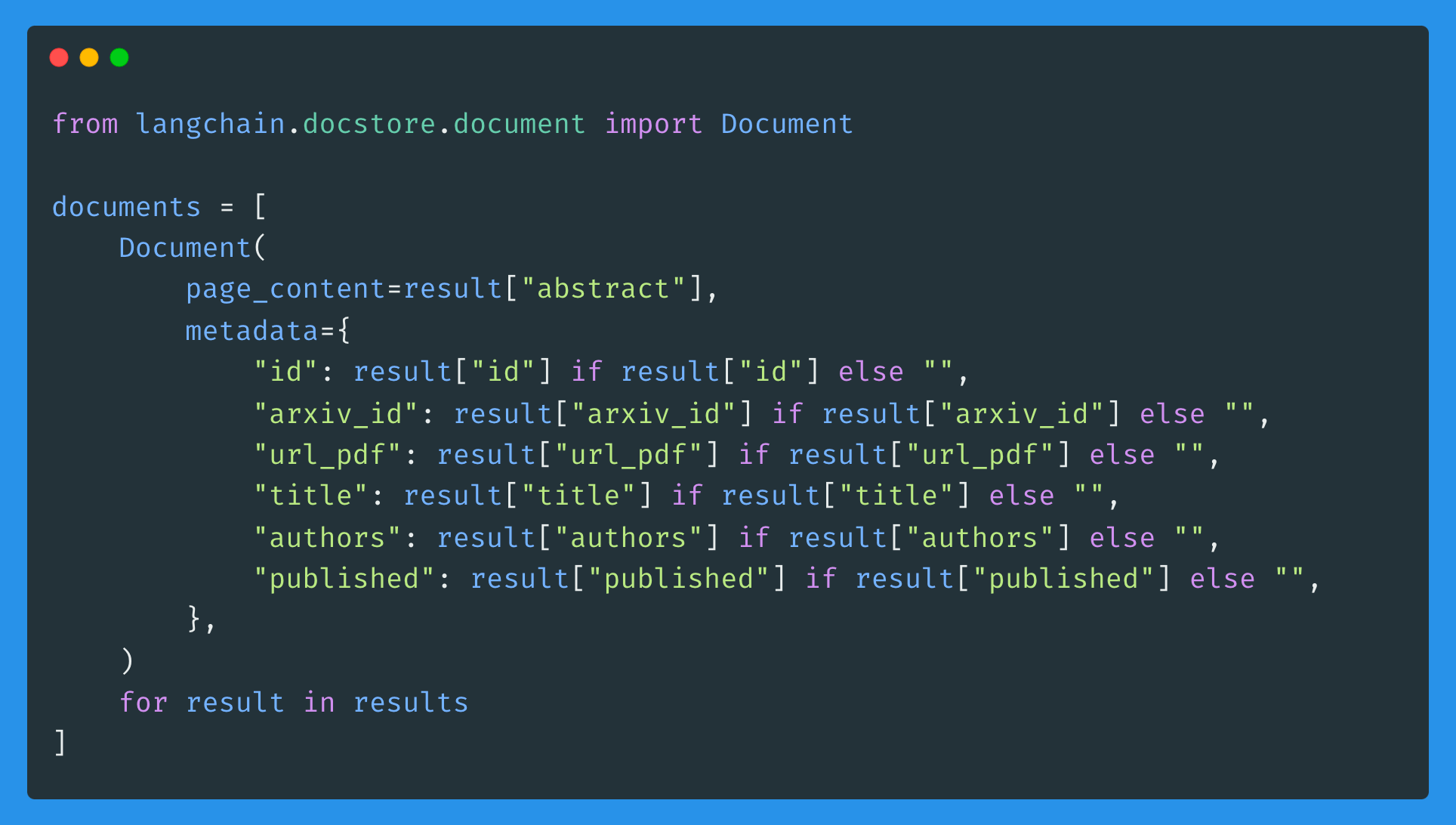
Once the results are extracted, we convert them from their raw JSON format into LangChain Documents to simplify chunking and indexing.
Document objects have two parameters:
page_content (str): to store the text of the paper’s abstract
metadata (dict): to store additional information. In our use case, we’ll keep: id, arxiv_id, url_pdf, title, authors, published
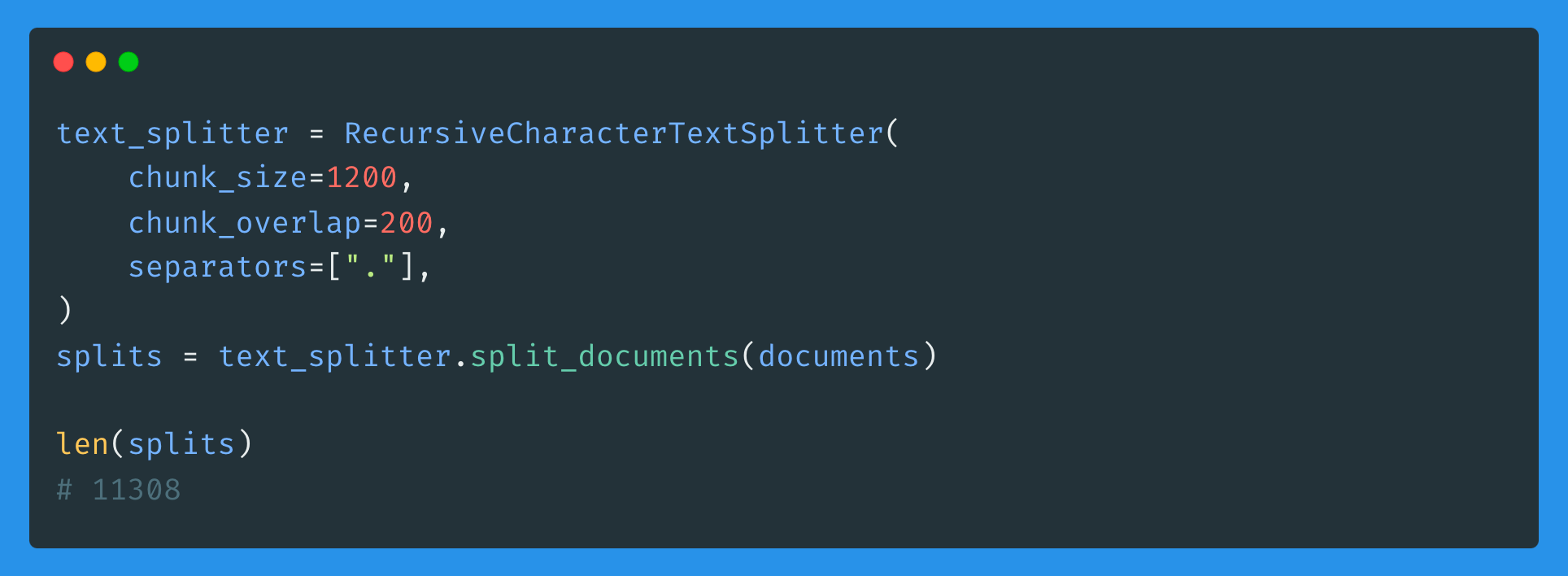
Before embedding the documents, we need to chunk them into smaller pieces. This helps overcome LLMs’ limitations in terms of input tokens and provides fine-grained information per chunk.
After chunking the documents with a chunk_size of 1200 characters and a chunk_overlap of 200, we end up with over 11K splits.

2 — Create an index on Upstash
To store document embeddings (and metadata) somewhere, we first have to create an index.
In this tutorial, we’ll use Upstash, a serverless database that is very cost-efficient.
