
The Tech Buffet #1: How To Design a System To Chat With Your Private Data
An overview of the global architecture

This is the first issue of my Substack newsletter, The Tech Buffet — I’m happy to see you here and I hope you like the name. Don’t hesitate to subscribe!
In this post, I’ll walk you through the process of designing a question-answering system that retrieves answers from an internal database of documents.
We will mainly focus on the system architecture and go through each component separately.
👉 If you want to leverage your company’s internal data and provide a relevant bot that doesn’t hallucinate, this post provides a starter solution 🎯.
Without further ado, let’s have a look 🔍

Why does it matter to build a custom Chatbot? 🤔
It’s all about precision and productivity
Building a Question Answering (QA) system over internal and private data is something most companies are interested in today as this provides undeniable benefits:
Accuracy: When you set the bot to provide answers that rely on the provided data only, you know it won’t hallucinate or invent things. This is of extreme importance especially if your data is domain-specific
Productivity: Interacting with a QA chatbot makes information retrieval almost instant and saves users a significant amount of time and effort
Maintainability: If your knowledge base grows or updates over time, you can take that into account during the data ingestion (more on this below) and update the bot
Extensibility: If you need to ingest a new data source (e.g. a database of PDF files or a dump of Emails), it’s as simple as configuring a new document loader (more details in the code section below)
Full control and privacy: If you build and deploy your personalized chatbot using open-source LLMs and vector databases, you can fully manage it on your infrastructure and avoid system outages or terrible SLAs
The Architecture 📐✏️
You can build and design a custom QA system over a set of documents in many ways.
In this post, we’ll look at an architecture that combines multiple components.
To help you understand how things are assembled together, we’ll follow this workflow step by step:
0 — Gather the data
Start by ingesting the data that represents your knowledge base. It can obviously come from different sources: PDF files, Emails, Confluence or Notion exports, web data, etc.

1 — Preprocess the documents
Once your documents are collected, split them into chunks (with or without overlaps). This is particularly useful to later avoid token limits imposed by many Large Language Models while embedding.

2 — Embed the documents
Use an embedding model from an open source (e.g. LLama2, Falcon) or a third-party service (OpenAI, Cohere, Anthropic) to convert previous chunks into vectors (a.k.a embeddings)
An embedding is a fixed-size numerical representation that makes it easy to manipulate text data and perform mathematical operations such as similarity measures.
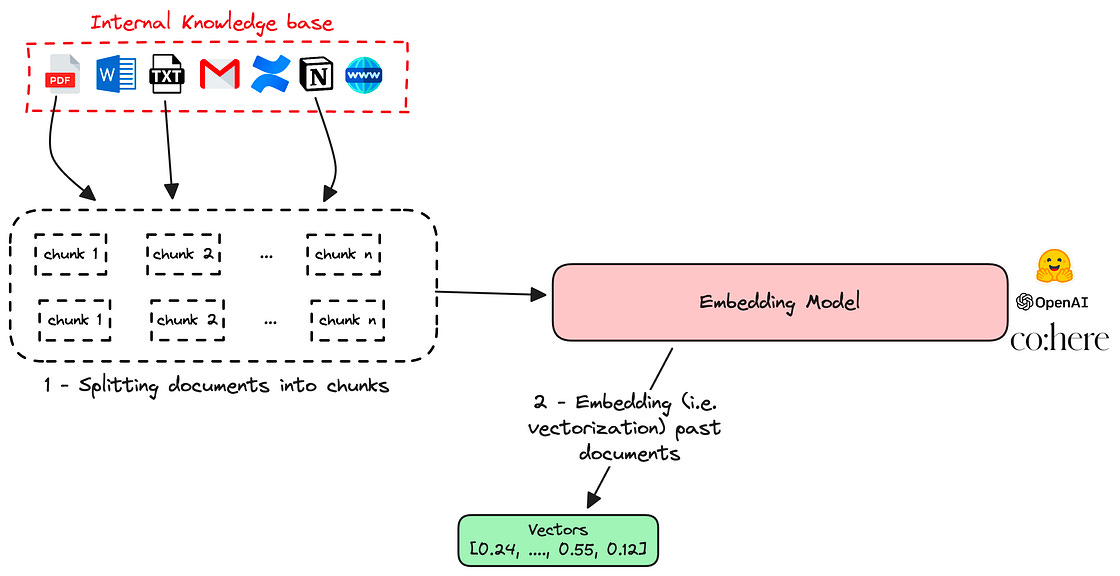
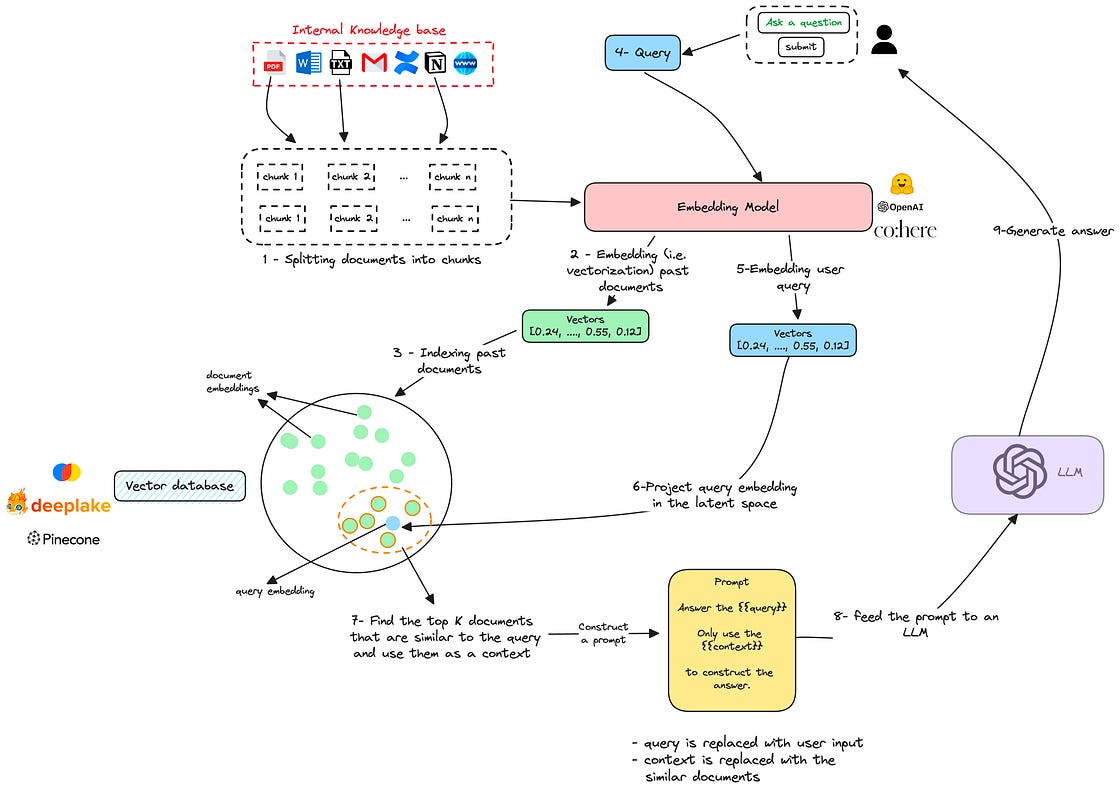
3 — Index embeddings in a vector database
Once the embeddings are computed, store them in a vector database like Chroma, Deeplake, or Pinecone.
Vector databases are useful for storing high-dimensional data and computing vector similarities.

4 — Ask a question
Once the documents are embedded and indexed in a vector database, you can send your query from a chat interface.

5 — Embed the input query
Use the same embedding model to convert your query into a vector

6 / 7 — Find relevant documents to the query
Use the vector database to find the document chunks that are most similar to your query. (As you may expect, the similarity measure is computed over the embeddings)
These chunks are not the final answer you’re looking for, but they are relevant to it: they basically contain elements of the response and provide context.

The number of similar chunks to fetch is a parameter to tune. In the code section below, we’ll set it to 4.
8 — Format a prompt
Use the previously extracted similar documents as a context inside a prompt.
This prompt will have the following structure, but you can customize it to meet your specific needs:
Answser the following question {question}
Only use this context to construct the answer:
%CONTEXT%
{context}
9 — Generate the answer
Once the prompt is created, feed it to an LLM to generate the answer.
The full picture
Here’s the full diagram to sum up the previous steps.
The key thing to remember from this architecture is the use of embeddings and a vector database as a proxy to find a relevant context to the query.
Conclusion
In this issue, we covered the building blocks of a question-answering system that provides answers from an internal knowledge base.
We understood how vector databases combined with LLMs act as a proxy to find the relevant document to the input query.
In the next issue, we’ll go through a starter Python implementation using Langchain to easily orchestrate the different components and have an end-to-end application.
Like it 🙌
So interesting ! thanks Ahmed