
The Tech Buffet #4: Turn Complex English Instructions Into Executable SQL With LLMs
An Overview of the Python Vanna Package

Hi 👋 my name is Ahmed. I write The Tech Buffet to help AI developers improve their code quality and ship end-to-end products faster.
Subscribe to get exclusive content.
In this issue, I’m going to show you how Vanna.ai leveraged modern LLM-based techniques to build a solution that generates complex SQL queries.
We’ll first cover how this solution works and what features it provides. Then, I’ll walk you through an interactive demo I built using it.
If you're interested in building AI products that deliver value, you may find Vanna’s story worth reading and sharing.
Without further ado, let’s have a look 🔍
With the ever-increasing adoption of LLMs, it’s now possible to develop applications with the most underrated programming language: English.
The promise is the following: you first express what you need in natural language. Then, an agent interprets your query and turns it into executable code.
Does this look unrealistic?
It did a few years ago. Now, with the fulgurant evolution of Generative AI, this has become easier than ever.
Enter Vanna
To quote the official website, Vanna.AI is a “Python-based AI SQL agent trained on your schema that writes complex SQL in seconds.”

When you start using it, you understand that Vanna is not only a Python package that you install on your environment. It’s a SaaS platform that allows you to:
Train and host custom models tailored to your databases
Call those custom models to generate SQL code from plain English instructions
As in typical SaaS products, the Python library is the SDK you’d use to interact with the services. Here’s a short demo:
To start using Vanna, you can create a free account here.
But before we dive into Vanna’s features and functionalities, let’s first understand how it works.
As a disclaimer, I don’t work for Vanna and I don’t have the exact knowledge of the architecture behind it. The following is based on hypotheses, conjectures and some reads.
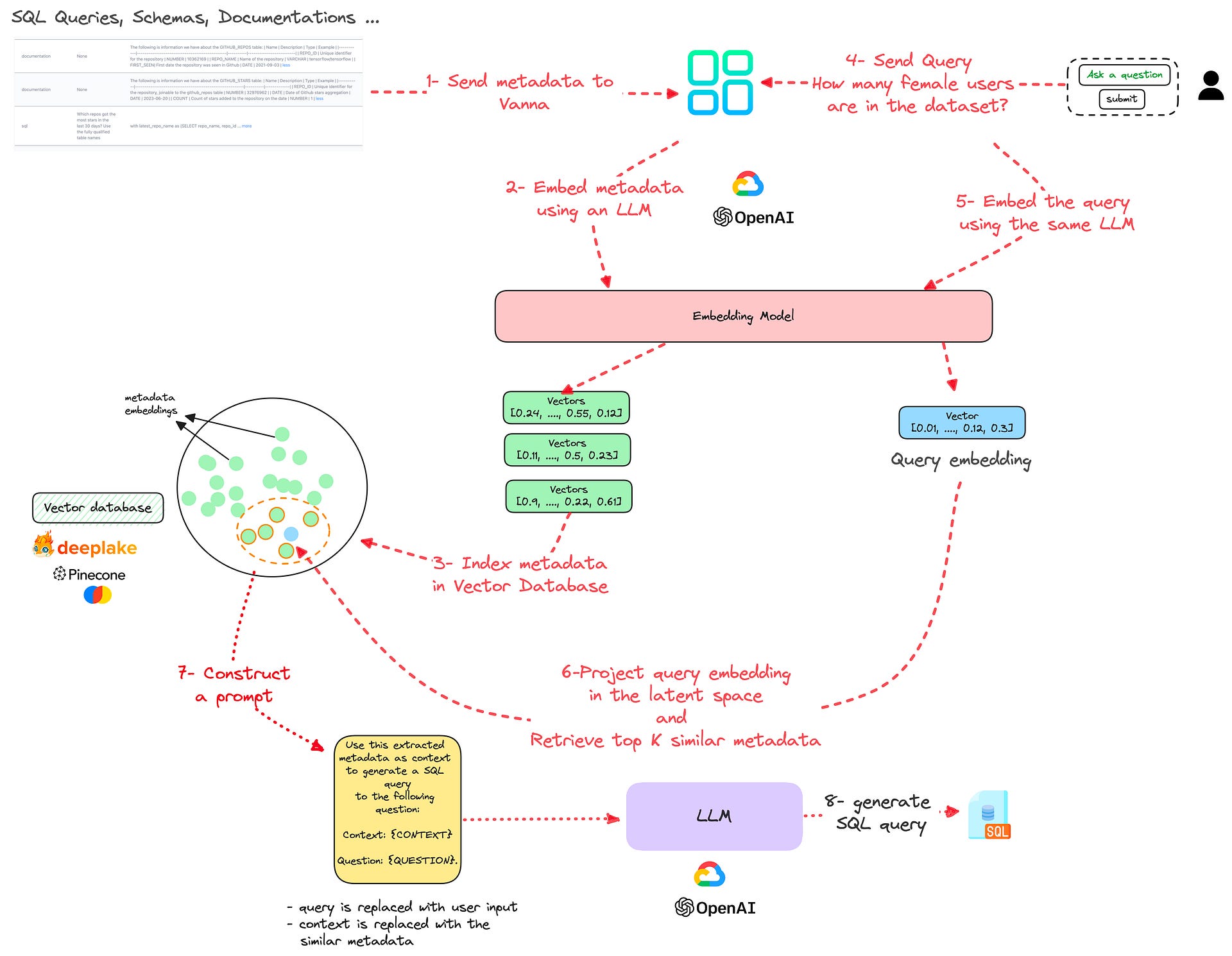
An overview of the training and the inference: From English instructions to SQL statements
When we talk about model training in this context, we do not mean training or fine-tuning a language model in the conventional sense.
In reality, training Vanna models for your databases relies on the Retrieval Augmented Generation (RAG) framework.
Instead of model fine-tuning, RAG builds a relevant context around the input query to boost the LLM generation capability.
If this doesn’t make much sense to you, don’t worry. I’m going to break it for you into the following steps:
1— You start by sending Vanna all the database metadata you can access (e.g. DDL Statements, documentation, and historical SQL queries).
This metadata, as the name suggests, doesn’t include the raw content. Good news, right?


2 — The metadata is then embedded using an LLM. The available models are ChatGPT, GPT4, and Google Bison. But Vanna also plans in the near future to incorporate open-source models as well.
The outputs of this step are numerical vectors (a.k.a. embeddings).

3 — The embeddings are indexed in a vector database. I don’t know which database Vanna is using underneath, but many choices (both proprietary and open-source) exist such as Pinecone, Chroma, or Deeplake.
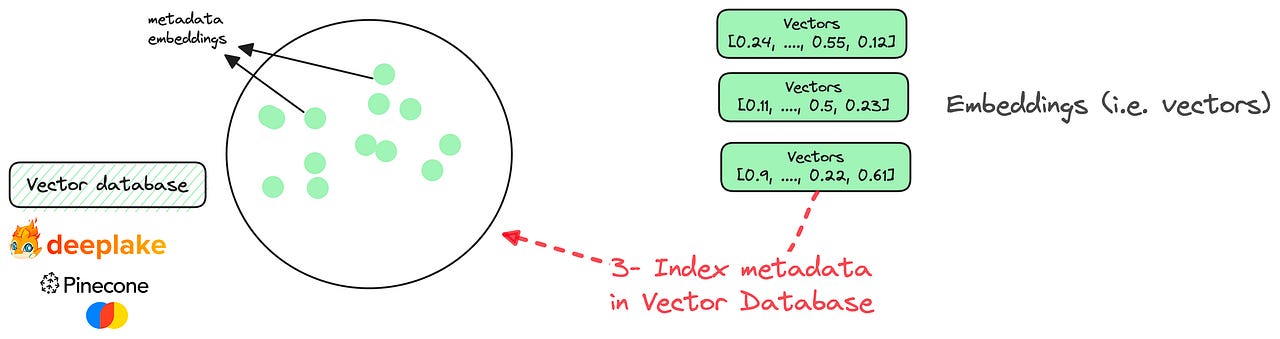
Up until now, we can assume that the Vanna “model” is almost fully trained on your metadata.
Now comes the inference (i.e. generation) step:
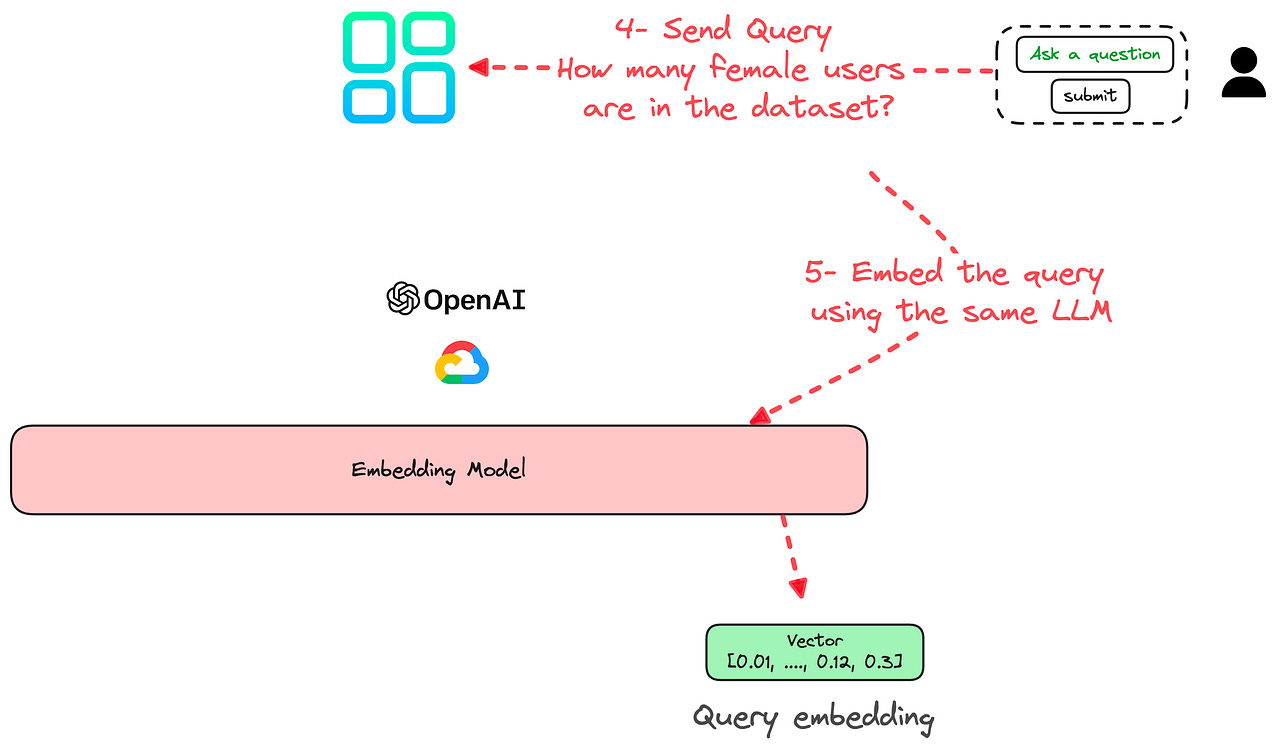
4 — You send Vanna your query in natural language. For e.g. “How many female users are in the dataset?”

5 — Your query is embedded using the same LLM as in Step 2: similarly, this produces a vector (i.e. an embedding) for your query.
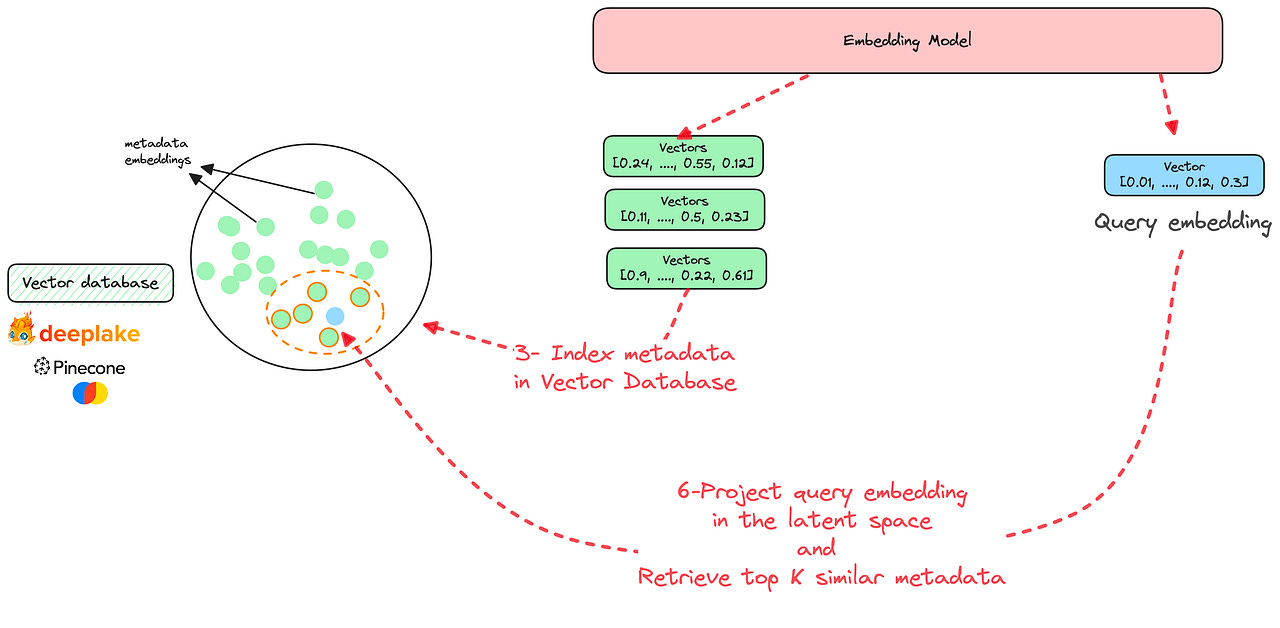
6 — Based on your query, the top K similar metadata are extracted from the vector database. This is done using similarity metrics on top of multi-dimensional vectors.
This extracted metadata doesn’t contain the answer you’re looking for, but it’s helpful in generating it.
We can assume that the extracted metadata contain some schemas that reference the gender column or previous queries asking about the number of women or men. (Remember, the question we’re asking is: “How many female users are in the dataset?”)
7 — We use the extracted metadata as a context in prompt to augment (hence the name) the generation capabilities of the LLM.
Use this extracted metadata as context to generate a SQL query
to the following question:
Context: {CONTEXT}
Question: {QUESTION}.
8 — The prompt is passed to the LLM to generate the query.
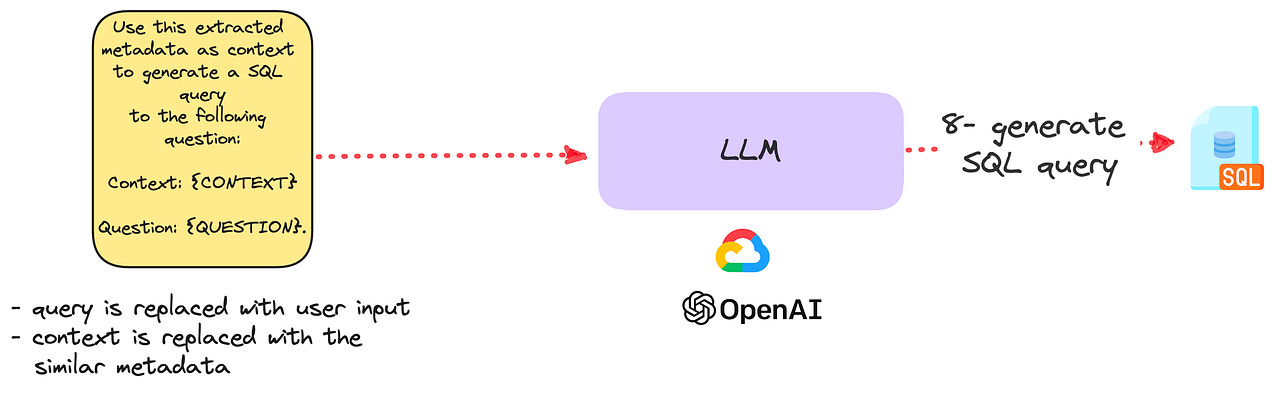
To sum up, here’s the full workflow that contains training and inference:
Here are a few comments before we move on:
The described steps and workflows may differ from the actual architecture. However, the underlying concepts remain the same.
Vanna incorporates the user instruction + the generated SQL in the training loop to improve the model continuously: this is not depicted in the workflows
To avoid prompt injections and attacks, Vanna uses some post-processing on the generated query or some advanced prompts.
Putting this into practice with some code
Less theory for now.
Let’s see how to train Vanna and use it to generate SQL queries.
You first need to load your API key and set a model name:
!pip install vanna
import vanna as vn
# Load and set your API key
api_key = vn.get_api_key('my-email@example.com')
vn.set_api_key(api_key)
# Set your model here
# This is a globally unique identifier for your model.
vn.set_model('my-model') Now, you can manually train Vanna by passing different types of metadata to the train method.
DDL statements:
vn.train(ddl="""
CREATE TABLE IF NOT EXISTS my-table (
id INT PRIMARY KEY,
name VARCHAR(100),
age INT
)
""")Documentation:
vn.train(documentation="Our business defines OTIF score as the percentage of orders that are delivered on time and in full")Previous SQL queries:
vn.train(sql="SELECT * FROM my-table WHERE name = 'John Doe'")Once the training is done, you can visualize the complete training dataset for sanity check:
To generate SQL queries, you can now simply call the ask method.
vn.ask("What are the top 5 artists by sales?")
Pretty cool, right?
Improving the official Vanna Streamlit Client💻
While playing with Vanna, I came across their Streamlit chat UI.
The app was really cool: it showed how you can build complex queries on the Look dataset, especially when joins are needed between multiple tables.
Here’s an example:

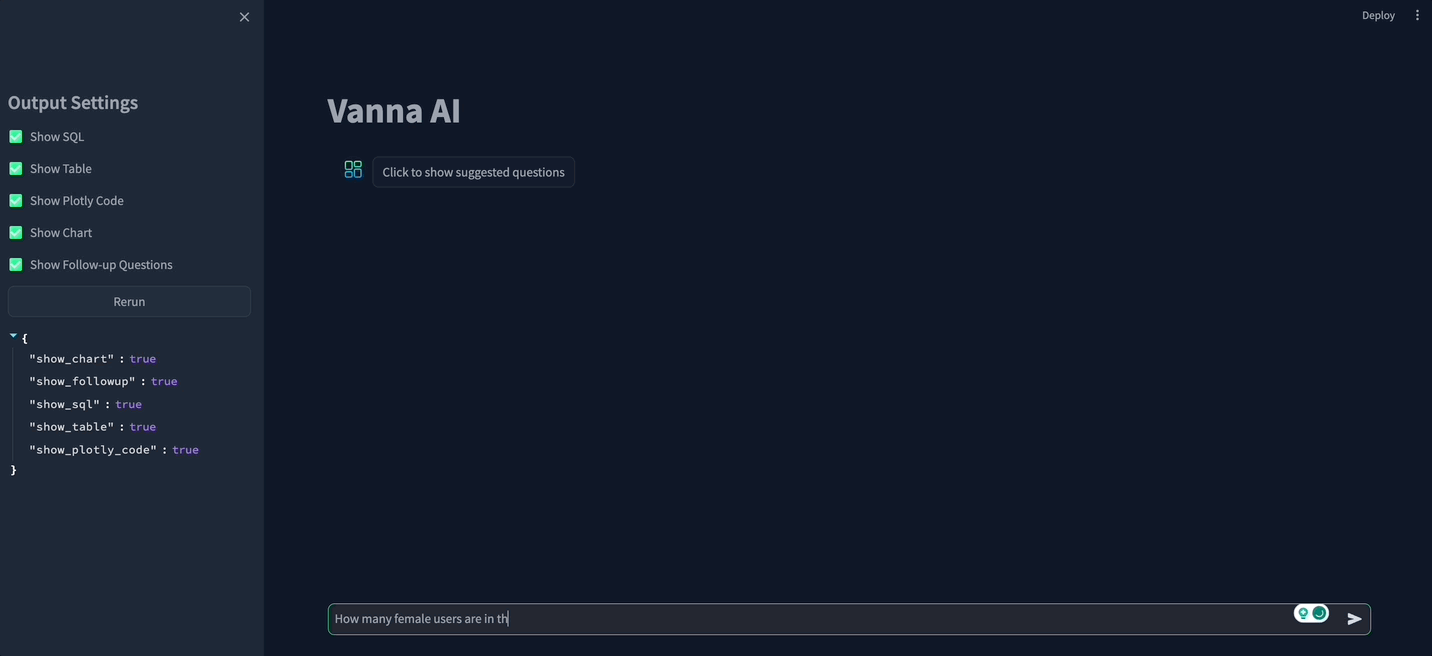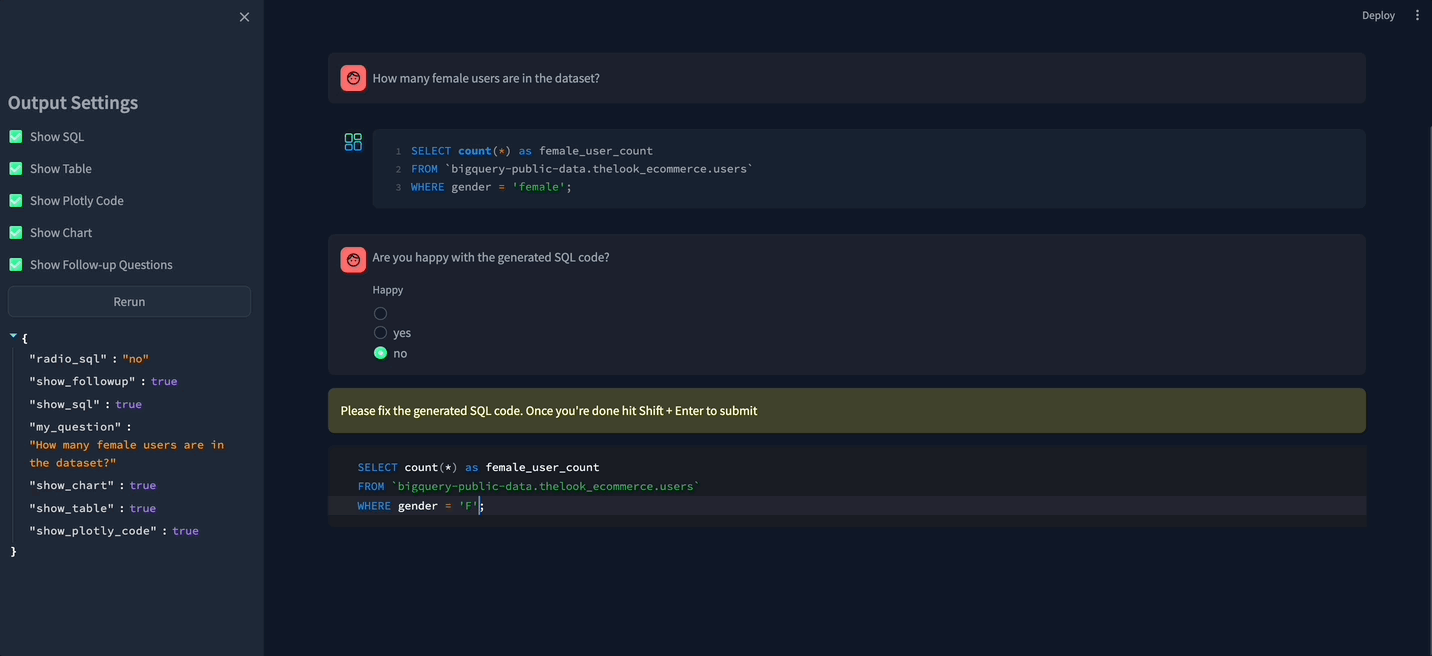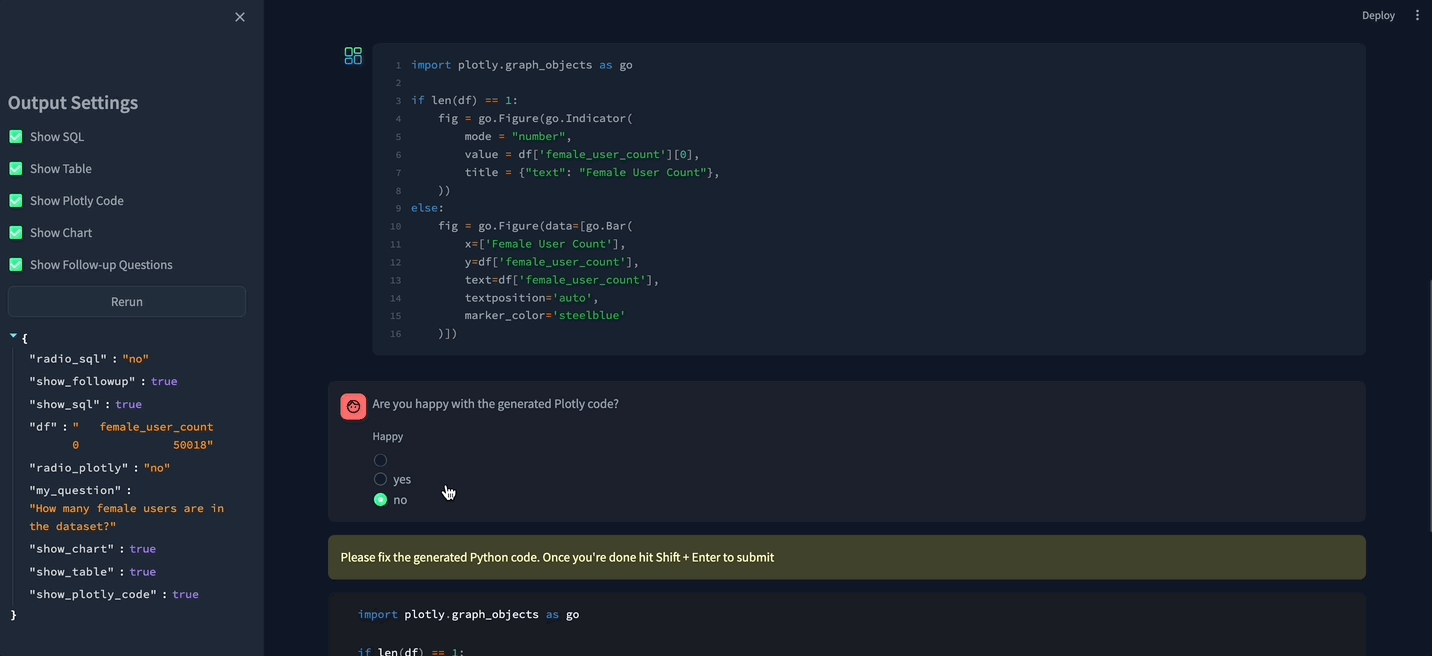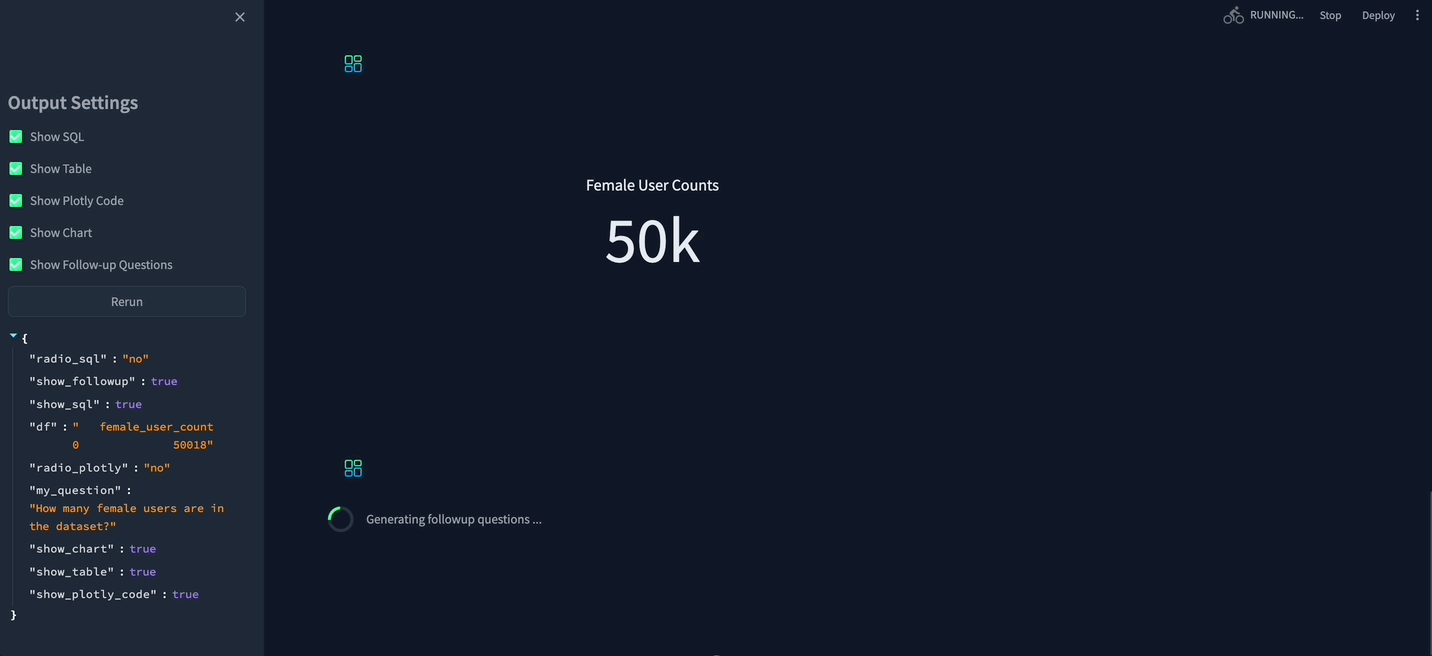
Once the SQL code is generated, Vanna runs it remotely (on the cloud) and sends the result back to the client.
It also generates a Python code to create Plotly graphs.

After generating the Plotly code, Vanna runs it remotely (again) and then sends the output Figure to Streamlit for rendering.

This doesn’t stop here: Vanna also suggests follow-up questions to increase the usage and gather more data for continuous training.
I made some improvements to the app: while experimenting with it, I noticed that the produced SQL / Python wasn’t always 100% error-free. So I added the possibility for the user to fix it.
I also made some changes to the UI, refactored the code a bit, and improved the caching mechanism for a better user experience.
Everything is documented in my PR that Vanna kindly approved. (Thank you Zain Hoda 👋).
Here’s what the app looks like after my modifications.
You can check the code here and feel free to send your PR if you want to contribute!
Conclusion
If you’ve made it this far, I hope you’ve enjoyed learning about Vanna as much as I did.
To me, this is not a toy product that will quickly vanish like most LLM-based apps.
That’ll be all for today, have a nice week-end!
Ahmed,