
The Tech Buffet #22: Why You Should Consider Weaviate As Your Ultimate Vector Database
Some insights from a 9-month project building RAGs for pharma

Hello everyone, Ahmed here. I write The Tech Buffet to deliver practical insights in machine learning and system design. This is based on my experience as an ML engineer, blogger and open source contributor.
In today’s issue, I explain my current motivations of selecting Weaviate as a production-ready vector database to power RAG systems.

A vector database is a critical component in Retrieval Augmented Generation (RAG) applications: besides storing the vectors and the metadata, it efficiently computes similarity measures and powers semantic search.
But picking the right vector database when building production-ready RAG applications is no easy task: this requires a close evaluation of the cost, the query performance, and the scalability. This is even more important when you process millions of vectors or expect real-time use.
I'm currently working at a pharma company and I've gone through this decision process. So, in this issue, I'll share with you why I think Weaviate is a good option for managing your vector data and building RAGs, especially if you're a developer with no particular experience in LLMs.
To make this tutorial easy to follow, I'll first load some data from a public API, index it in Weaviate, and experiment with some of its cool features.
Here's the agenda
Load research papers from the Papers With Code public API
Setup Weaviate locally
Index the data in batches
Overview of Weaviate search functionalities:
vector search
keyword search
hybrid search
re-ranking
advanced filtering
Generative search: turning your database into a RAG system
1—Load research papers from the Papers With Code public API 🔌
To experiment with Weaviate features, we first need to ingest some data. Many datasets are available out there.
The one we'll experiment today with consists of research papers about Large Language Models.
We'll extract this dataset from the public API of paperswithcode.
To collect this dataset, you need to run the following function:

This dataset contains ~11K paper abstracts with the following attributes and metadata:

2—Setup Weaviate locally ⚙️
Weaviate is an open-source, AI-native vector database that helps developers create intuitive and reliable AI-powered applications.

You can use Weaviate in different ways:
Via a docker-compose locally
Via Kubernetes by deploying it on cluster
Via Weaviate Cloud Services (WCS), the managed offering
At my company, we deployed Weaviate on Kubernetes but in this tutorial, we’ll use docker-compose for demo purposes.
The setup is straightforward.
Create an empty
weaviate_datafolder to store Weaviate data on the hostCreate a docker-compose file with this configuration:
Enabled modules:
text2vec-palm,reranker-cohere,generative-palmAUTHENTICATION_APIKEY_ALLOWED_KEYS: 'admin'
AUTHENTICATION_APIKEY_USERS: 'ahmed'

Run this command:
docker-compose up

To check that Weaviate started successfully, you can hit this URL

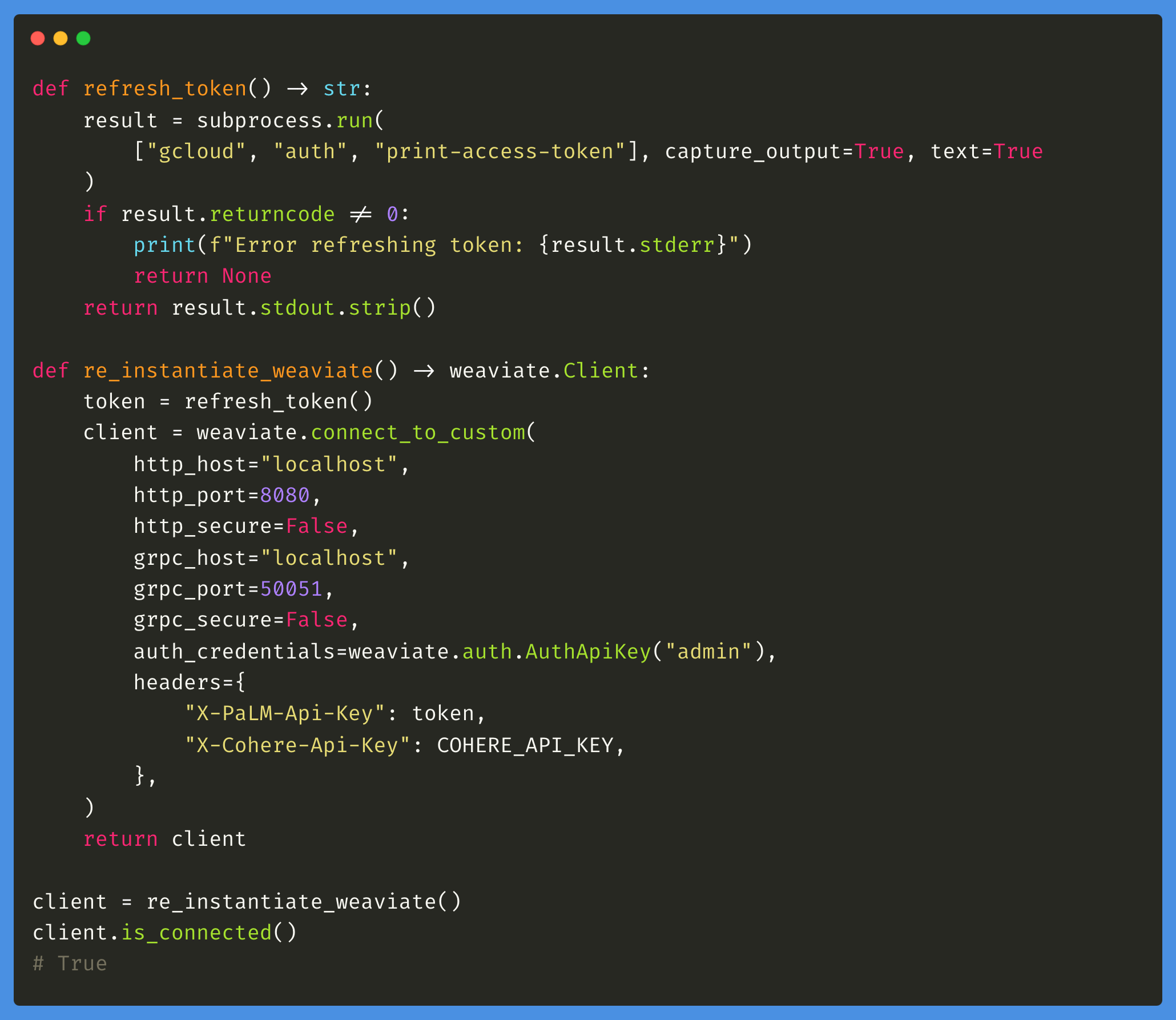
After launching Weaviate, you must create a client to interact with it.
This client can have additional credentials to connect to other third-party cloud services like OpenAI, VertexAI, or Cohere.
Why would a vector database need these connections?
Weaviate can take care of other things than storing your vectors and computing similarities.
It can embed the data while indexing it
It can perform document reranking after retrieval
It can perform a RAG operation by answering questions based on search results
and more…
In this tutorial, I'll connect Weaviate to VertexAI to power text embedding and generation and connect it to the Cohere API for the reranking task.
3—Index the data in batches 🗂️
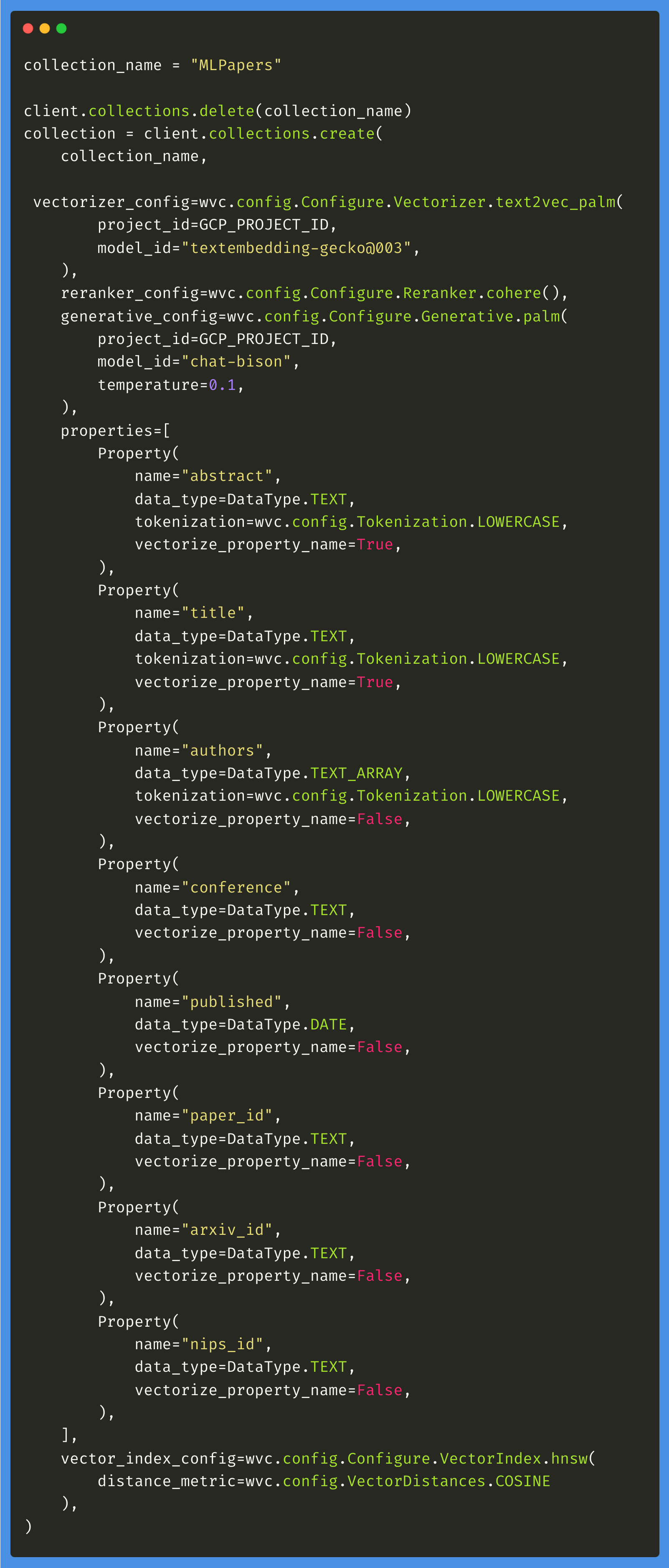
Before indexing the data into Weaviate, we must create a collection and define the schema.
This is done via the create method that defines:
The collection name: MLPapers
The properties (or fields)

The vectorizer that'll be used to embed the data while indexing it

The generator that'll be used to generate answers based on retrieved documents (To perform RAG directly in Weaviate)

Here’s the full code:
After the collection is created, you can index the data in batches. This is another useful functionality of Weaviate that speeds up the indexing process.

Once the indexing is complete, we can check the number of vectors using the aggregate method:
collection.aggregate.over_all(total_count=True)
# AggregateReturn(properties={}, total_count=10592)4—Weaviate search functionalities 🔍
Weaviate has multiple search options. We’ll review some of them in this section.
1. Vector Search
The obvious search method is based on vector similarities. Here's how to do it:

Behind the scenes, Weaviate first embeds the text query using the vectorizer, then fetches the similar results from the collection.
The response contains a list of objects and each one has the following structure.

By inspecting the three retrieved documents, we notice that they match the query accurately.

2. Keyword Search
Weaviate handles the keyword search by using the BM25 algorithm.
Keyword search is a simple technique that relies on string matching only.
You can run a keyword search in Weaviate by calling the bm25 method.

This gives the following results:

After reading these documents, they appear less relevant than the previous ones. They mention the words “fine-tuning” or “LLMs” but don’t necessarily discuss the process of model fine-tuning.
Keyword search is a useufl functionality when you need to match specific terms that an embedding model doesn’t necessarily know or represent well (e.g. a drug nomenclature or an e-commerce product name)
3. Hybrid Search
One feature that I find particularly useful in Weaviate is hybrid search.
