

The Tech Buffet #23: What Nobody Tells You About RAGs
A deep dive into why RAG doesn't always work as expected: an overview of the business value, the data, and the technology behind it.


The Tech Buffet provides in-depth tutorials and technical reviews of topics in ML and programming. Consider supporting it by subsribing.
Building a RAG to «chat with your data» is easy: install a popular LLM orchestrator like LangChain or LlamaIndex, turn your data into vectors, index those in a vector database, and quickly set up a pipeline with a default prompt.
A few lines of code and you call it a day.
Or so you’d think.
The reality is more complex than that. Vanilla RAG implementations, purposely made for 5-minute demos, don’t work well for real business scenarios.
Don’t get me wrong, those quick-and-dirty demos are great for understanding the basics. But in practice, getting a RAG system production-ready is about more than just stringing together some code. It’s about navigating the realities of messy data, unforeseen user queries, and the ever-present pressure to deliver tangible business value.
In this issue, we’ll first explore the business imperatives that make or break a RAG-based project. Then, we’ll dive into the common technical hurdles — from data handling to performance optimization — and discuss strategies to overcome them.
Disclaimer: The insights shared here don’t represent my employer and come from my personal experiences, research, and more than a few late-night coding sessions.
1 — Clarify the business value from the start: the context, the users, and the data
“Why should we bother building a RAG in the first place?”

Before writing a single line of code, it’s critical to understand why a RAG (Retrieval-Augmented Generation) is even needed from a business perspective. This might seem obvious, but many developers neglect this part, rushing into implementation headfirst without clearly defining long-term objectives.
Let’s keep you from losing time in the future. Here are some business requirements to consider before starting a RAG/LLM-based project. These principles also apply to general ML projects:
→ Clarify the context: Know your users and what they do. Formulate their main business issue in simple terms, put yourself in their shoes, dissect what they do, and then discuss how RAGs and LLMs can help. Take sample questions and simulate how the system would handle them.
→ Educate non-technical users on the capabilities and limitations of generative AI. Since this is a new field, this is very helpful. This can be achieved through workshops, training sessions, and practical demonstrations that use RAG systems. For example, I’ve seen that internally crafted prompting guides are often helpful for getting started with interacting with LLMs.
→ Understand the user journey: What types of questions will they answer with the RAG? What are the outputs to expect from such a system? How will the generated answers be used down the line?
Most importantly, you must know how your RAG will integrate into an existing workflow. This foresight will anticipate further developments, such as whether the RAG will be embedded into a browser extension, an API endpoint, or a Word plugin.
Generating an answer using a RAG system is simple. What’s complex, however, is driving practical value from it.
Keep this in mind: the business won’t come to you and play with your fancy models unless those change and improve their ways of working.
→ Anticipate the data to be indexed: Qualify it, map it to the users, and understand why and how it will be used to form a good answer when the RAG pipeline is triggered. This will determine what processing and metadata should be implemented. After qualification, you’ll eventually need to set up a data acquisition strategy: purchasing, leveraging internal data, discarding unnecessary data, or sourcing from open resources (open data, GitHub repos, etc.).
If a process heavily relies on business requirements, it must be identified early on at this step.
→ Define success criteria: What is a correct answer? What are the key success factors? How can we establish a clear way to compute the ROI? These metrics should not be evaluated only when the project is done. They should be iterated continuously throughout the project to catch early mistakes, easy bugs, and inconsistencies.
Personal note: If the business asks you to build a RAG, one possible reason could be they’ve seen the competition doing it, (FOMO is a real thing, my friend). My advice to you in this situation is to challenge this request first. Very often, what the business needs can be less complex than we think.
2 — Understand what you’re indexing
After mapping and qualifying the data sources needed to build a RAG, you’ll quickly identify different kinds of modalities that will be indexed upon further discussion with the business.
text
images and diagrams
tables
code snippets
Each of these modalities will be processed differently, turned into vectors, and used in retrieval.
There are different approaches to combining multimodal data: here’s a common one that deals with text, tables, and images:
text data is chunked and embedded with an embedding model
tables are summarized with an LLM and their descriptions are embedded and used for indexing. After it’s retrieved, a table is used as-is, in its raw tabular format.
code snippets are chunked in a special way (to avoid inconsistencies) and embedded using a text embedding model
images are converted into embeddings using a multi-modal vision and language model — When retrieval is performed, the same multimodal LLM will take in your text query convert it to a vector and search related images in the vector db.
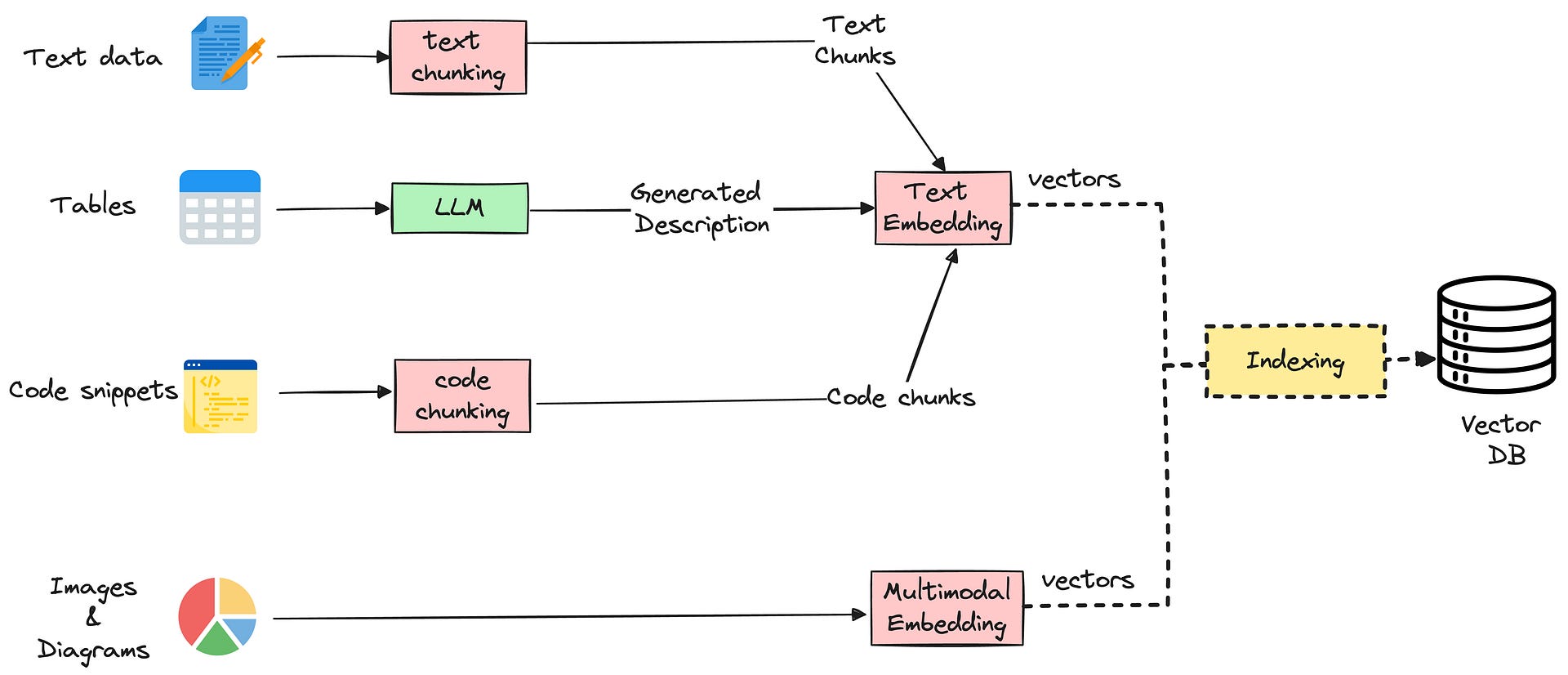
Additional notes:
The vectors you index are not necessarily the vectors you retrieve: you can do things differently: For example, you can index sentences by the paragraphs they occur into, by the questions they answer, or by their summary. Check this post to learn more.
There are a lot of great resources on multimodal RAGs. Check this blog from LlamaIndex for a deep dive.
3 — Improve chunk quality — garbage in, garbage out
Before indexing text data, you need to break it into smaller pieces called chunks. Chunks are the text snippets the vector database retrieves and passes to the LLM as a context to generate an answer.
So it’s obvious that the chunks' quality impacts the answer.
If the chunks:
are pulled out of their surrounding context (if cut in the middle for example)
include irrelevant data that doesn’t answer the question
contradict each other
they’ll provide a poor answer.
There are different chunking techniques that you can explore here and here.
Other techniques depend on the data type (raw text, markdown, code).
However, what works best in general is to analyze the data precisely and come up with a chunking rule that makes sense from a business perspective:
Here are some tips:
Leverage document metadata like table of contents, titles, or headers to provide contextually relevant chunks. For example, a chunk that overlaps between an introduction and the first chapters is not consistent and rarely makes sense
There’s no rule of thumb regarding chunk size. If your documents are wordy and express a single idea in relatively long paragraphs, the chunk size would be longer than documents that are written in bullet points
Some data don’t need chunking because it’s relatively short and self-contained. Imagine building a RAG-based system on JIRA tickets: you won’t need chunking for that.
Note on semantic chunking: this method generates chunks that are semantically relevant. It’s however time consuming since it relies on embedding models underneath.
Resources about chunking:
4 — Improve pre-retrieval
Before your query reaches the RAG system, you can refine it with additional processing steps.
These steps are called pre-retrieval: they optimize the input query, ensuring the system retrieves the most relevant and high-quality documents.
Here are some key pre-retrieval steps to consider ⤵️
Keep reading with a 7-day free trial
Subscribe to The Tech Buffet to keep reading this post and get 7 days of free access to the full post archives.