
The Tech Buffet #14: A 3-Step Approach To Evaluate Your LLM-based Applications
Stop selecting the parameters of your RAG randomly


Hello everyone 👋, Ahmed here. Welcome to The Tech Buffet, where I share practical insights to build industry-ready ML (and LLM) applications.
Tuning your RAG to get optimal performance takes time as this depends on various interdependent parameters: chunk size, overlap, top K retrieved docs, embedding models, LLM, etc.
The best combination often depends on your data and your use case: you can’t simply plug in the settings you used in the last project and hope for the same results.
Most people don’t address this issue properly and pick parameters almost randomly. While some are comfortable with this approach, I decided to tackle the problem numerically.
Here’s where evaluating your RAG comes in.
In this issue, I’ll show you a quick method you can follow to efficiently and quickly evaluate your RAGs across two tasks:
Retrieval
Generation
By mastering this evaluation pipeline, you can iterate, perform multiple experiments, compare them with metrics, and hopefully land on the best configuration
Let’s see how this works 👇.
1—Create a synthetic dataset
Evaluating an LLM often requires annotating a test set manually. This takes time, requires domain expertise, and is prone to human errors.
Hopefully, LLMs can help us with this task.
Sample N chunks from your data. For each chunk, instruct an LLM to generate K tuples of questions and answers.
After the generation is complete, you will obtain a dataset of N*K tuples, each one having (question, answer, context).
Ps: The context here is the original paragraph and its metadata

Here’s the prompt I used in one of my projects:
Create exactly {num_questions} questions using the context and make sure each question doesn't reference
terms like "this study", "this research", or anything that's not available to the reader.
End each question with a '?' character and then in a newline write the answer to that question using only
the context provided.
Separate each question/answer pair by "XXX"
Each question must start with "question:".
Each answer must start with "answer:".
CONTEXT = {context}2—Run your RAG over each synthetic question
Once the dataset is built, you can use your RAG to perform predictions on each question.
This will generate answers backed by a set of retrieved sources.
For each question, make sure you list the retrieved documents: this will later be useful for evaluation.

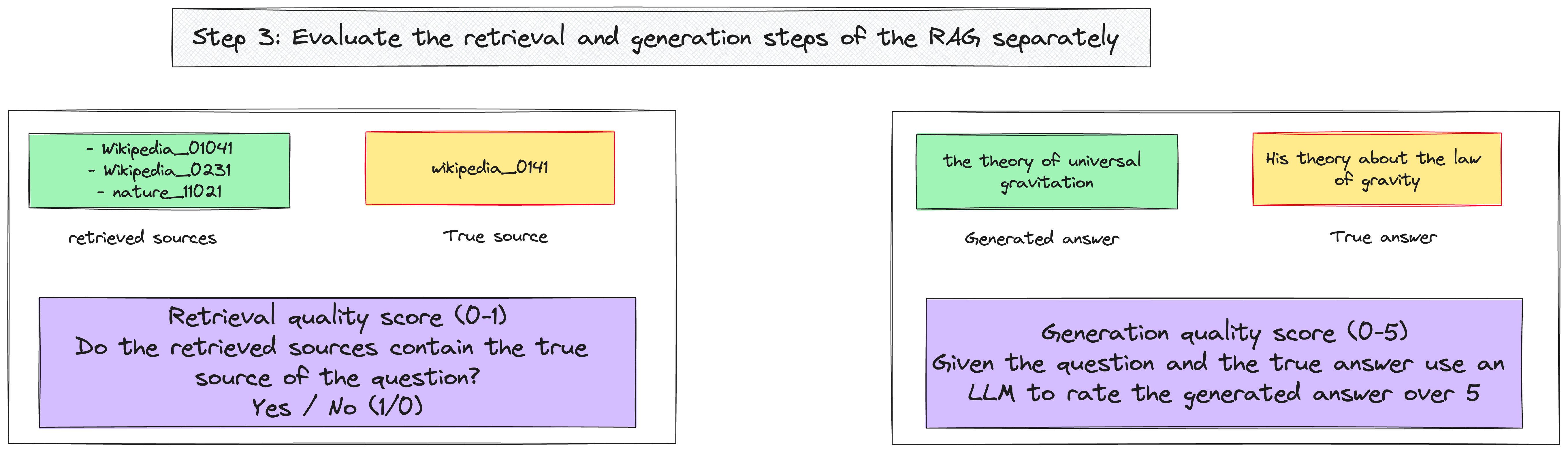
3—Compute two evaluation metrics
Now, you can compute two scores for each question:
A retrieval score to assess the relevance of the retrieved documents
This score can be binary (1/0 for each prediction) and tells whether the true source for each question is in the list of the retrieved sources.A quality score to evaluate the generated answer given the question and the ground-truth answer. Again, an LLM can be used in this task to produce such evaluation over 5.
Here is the prompt I used:Your job is to rate the quality of a generated answer given a query and a reference answer. QUERY = {query} GENERATED ANSWER = {generated_answer} REFERENCE ANSWER = {reference_answer} Your score has to be between 1 and 5. You must return your response in a line with only the score. Do not return answers in any other format. On a separate line provide your reasoning for the score as well
After obtaining these scores for each question, average them over the dataset to obtain the final two metrics.
Resource:
Interested to learn more about RAGs? Feel free to check my previous issues:
Get to know other newsletters I like on this platform 👇


This was a short issue for today. Happy Sunday! 👋
@Ahmed Beses, these are helpful articles on LLM